
💡 Intro
백앤드 개발자가 기본적으로 알아야 하는 개념을 다시 한번 정리할 겸 하여 백앤드 개발자를 준비하면서 받았던 면접 질문, 그동안 학습하였던 내용 그리고 예상 가능한 질문을 정리해 보았습니다. 기본적인 백앤드 개념, 서버와 시스템에 대한 이해도의 내용을 중점으로 하였습니다. 당연하게도 정리돼 있는 질문들에 대해 딥 한 질문들이 들어올 수 있으니 깊이 있게 공부하셔야 합니다. 또한 ‘이 정도 질문들에 스스로 대답할 수 있는 정도의 기본기를 내가 가지고 있구나’를 확인하는 방향으로 공부해도 좋을 것 같습니다.😊
🔎 개발 면접 질문 - 네트워크
1. HTTP와 HTTPS에 대해 설명해 주세요.
HTTP(Hyper Text Transfer Protocol)이란 데이터를 주고 받기 위한 프로토콜이며, 서버/클라이언트 모델을 따릅니다. 또한 HTTP는 평문 데이터를 전송하는 프로토콜이기 때문에, HTTP로 중요한 정보를 주고 받으면 제 3자에 의해 조회될 수 있습니다. 이러한 문제를 해결하기 위해 HTTP에 암호화가 추가된 프로토콜이 HTTPS입니다.
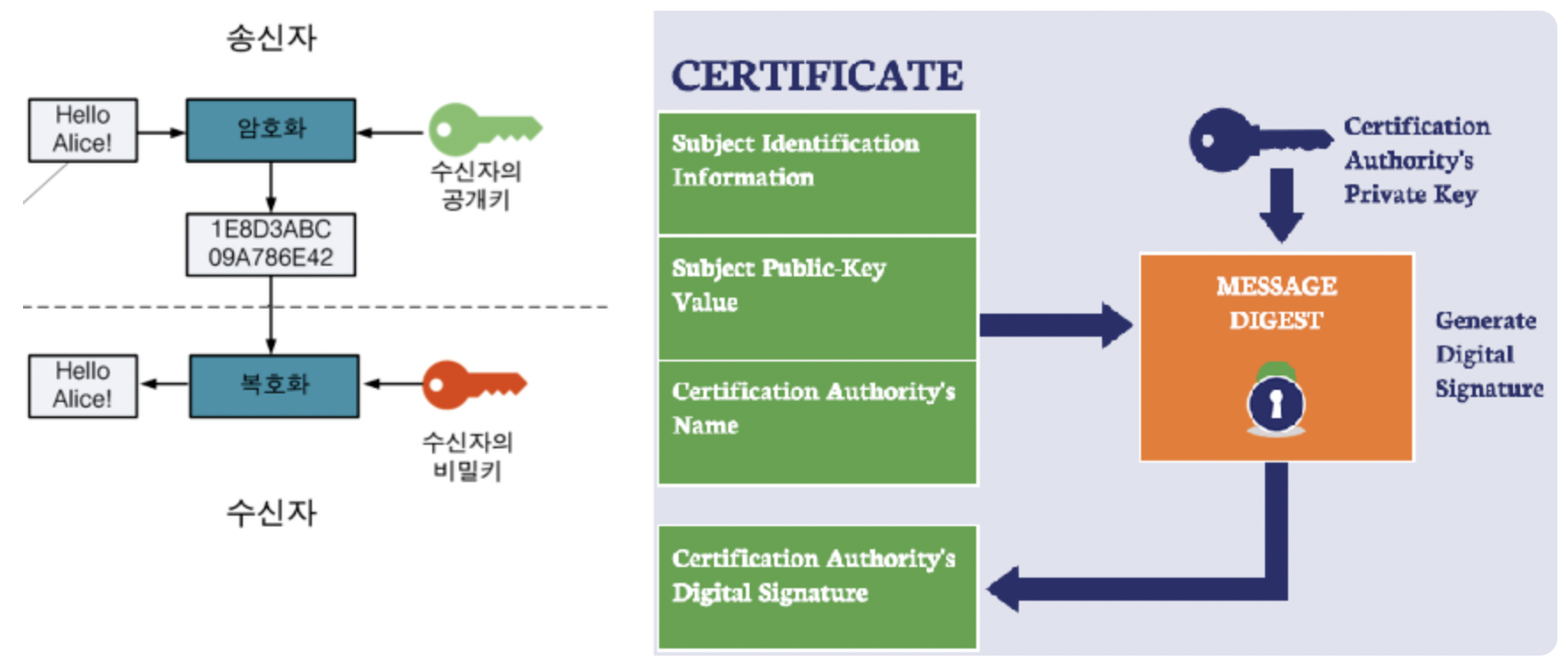 이미지 1. HTTP와 HTTPS의 차이
이미지 1. HTTP와 HTTPS의 차이
공개키(인증서)로 암호화된 메세지는 개인키를 가지고 있어야만 복호화가 가능하기 때문에, 서버(기업)을 제외한 누구도 원본 데이터를 얻을 수 없습니다.
2. HTTP Method에 대해 설명해 주세요.
- GET, POST, PUT, DELETE가 있습니다.
- GET은 클라이언트에서 서버로 어떠한 리소스로부터 정보를 요청하기 위해 사용되는 메소드입니다. 서버에서 어떤 데이터를 보여줄 때 값, 내용, 상태들을 바꾸지 않을 경우에 사용됩니다.또한, 데이터가 헤더에 추가되어 전송되므로 URL에 데이터가 노출되기 때문에, 보안적으로 중요한 데이터는 포함시켜서는 안됩니다.
- POST는 리소스를 생성,업데이트하기 위해 서버에 데이터를 보내는 데 사용하는 메소드 입니다. 즉, 서버상의 데이터 값이나 상태를 바꿀 때 사용됩니다. 또한 GET과는 달리 데이터를 바디에 추가여 전송하기 때문에, 완잔하게 안전한 것은 아니지만 조금 더 안전합니다.
- GET과 POST의 차이점으로는 GET요청은 캐시가 되며 멱등성이 보장되지만, POST요청은 캐시가 되지 않고 멱등성이 보장되지 않습니다.
3. HTTP의 주요 상태코드에 대해 설명해 주세요.
- 200 : OK, 요청이 성공적으로 처리되었습니다. 요청에 따른 응답을 반환합니다.
- 404 : 서버는 요청받은 리소스를 찾을 수 없습니다. 예를 들어, 브라우저에서는 알려지지 않은 URL을 의미합니다.
- 503 : 서버가 요청을 처리할 준비가 되지 않은것을 의미합니다. 일반적인 원인은 유지보수를 위해 작동이 중단되거나, 과부하가 걸린 서버일 경우 발생할 수 있습니다.
또한 1번 대 부터 5번 대 상태 코드의 대략적인 의미는 다음과 같습니다.
- 1xx (정보) : 요청을 받았으며 프로세스가 계속 진행합니다.
- 2xx (성공) : 요청을 성공적으로 받았으며 인식했고 수용합니다.
- 3xx (리다이렉션) : 요청을 위한 추가 작업 조치가 필요합니다.
- 4xx (클라이언트 오류) : 요청의 문법이 잘못되었거나 요청을 처리할 수 없습니다.
- 5xx (서버 오류) : 서버가 명백히 유효한 요청에 대한 충족을 실패했습니다.
4. 쿠키(Cookie)와 세션(Session)의 차이점에 대해 말해 주세요.
- 쿠키는 사용자의 컴퓨터에 저장하는 작은 기록 정보 파일입니다. HTTP에서 클라이언트의 상태 정보를 PC에 저장했다가 필요시 정보를 참조하거나 재사용할 수 있습니다.
- 세션은 일정 시간동안 같은 사용자로부터 들어오는 일련의 요구를 하나의 상태로 보고, 그 상태를 유지시키는 기술입니다. 즉, 방문자가 웹 서버에 접속해 있는 상태를 하나의 단위로 보고 그것을 세션이라고 합니다.
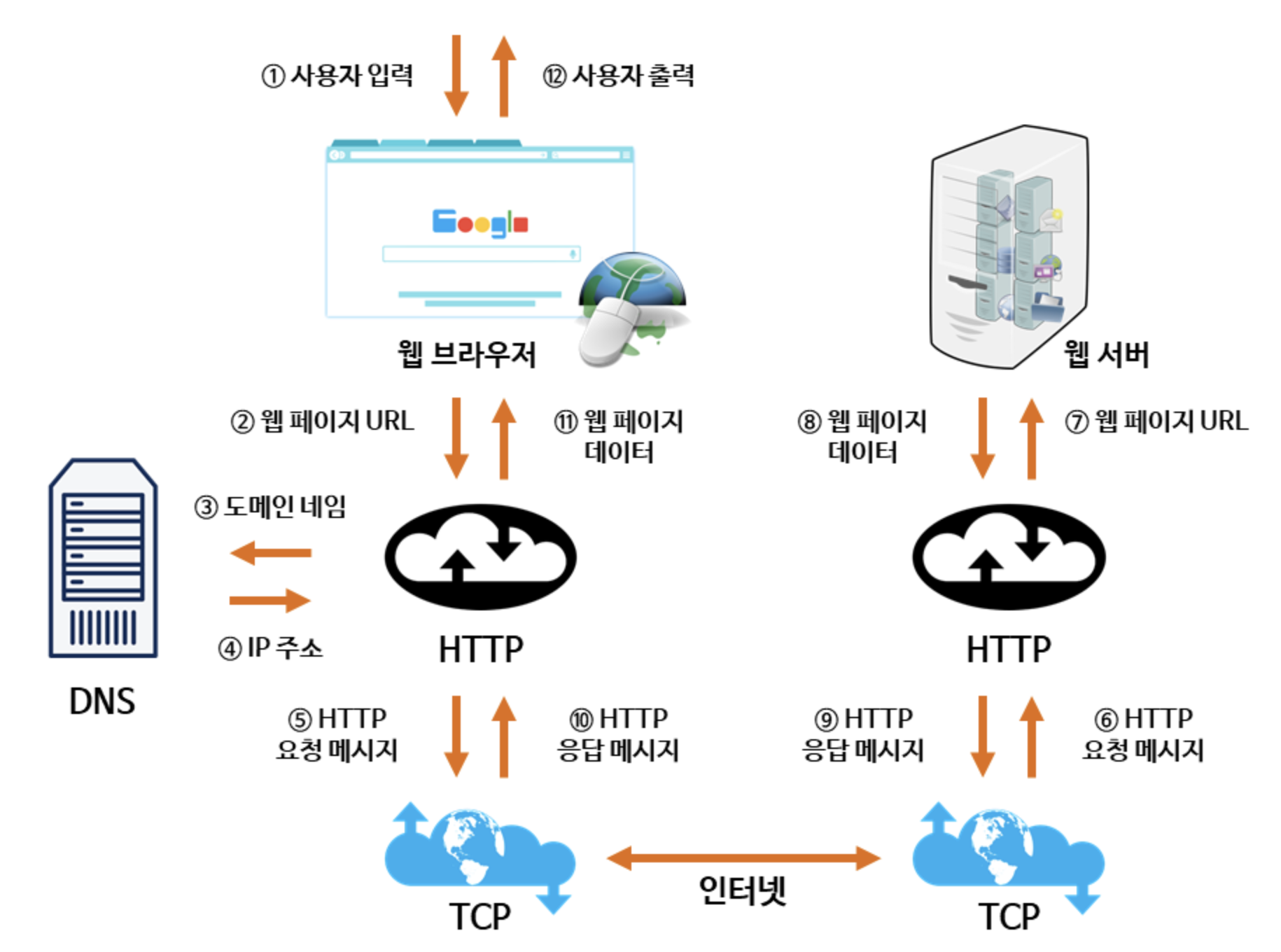
5. https://www.google.com/에 접속할 때 생기는 과정에 대해 설명해 주세요.(웹 동작 방식 이해)
이미지 2. 웹 동작 방식 이해
- 사용자가 브라우저에 URL(https://www.google.com/)을 입력
- 브라우저는 DNS를 통해 서버의 진짜 주소를 찾음
- HTTP 프로토콜을 사용하여 HTTP 요청 메세지를 생성함
- TCP/IP 연결을 통해 HTTP요청이 서버로 전송됨
- 서버는 HTTP 프로토콜을 활용해 HTTP 응답 메세지를 생성함
- TCP/IP 연결을 통해 요청한 컴퓨터로 전송
- 도착한 HTTP 응답 메세지는 웹페이지 데이터로 변환되고, 웹 브라우저에 의해 출력되어 사용자가 볼 수 있게 됨
6. TCP와 UDP의 차이를 설명해 주세요.
- TCP는 연결형 서비스로 3-way handshaking 과정을 통해 연결을 설정하기 때문에 높은 신뢰성을 보장하지만, 속도가 비교적 느리다는 단점이 있습니다.(1:1 통신방식)
- UDP는 비연결형 서비스로 3-way handshaking을 사용하지 않기 때문에 신뢰성이 떨어지는 단점이 있지만, 데이터 수신 여부를 확인하지 않기 때문에 속도가 빠르다는 장점이 있습니다.(1:1 or 1:N or N:N 통신방식)
6-1. 그렇다면 3 way-handshake와 4 way-handshake를 설명해 주세요.
- 3 way-handshake란 TCP 네트워크에서 통신 하는 장치가 서로 연결이 잘 되었는지 확인하는 방법입니다. 송신자와 수신자는 총 3번에 걸쳐 데이터를 주고 받으며 통신이 가능한 상태인지 확인합니다.
- 4 way-handshake란 TCP 네트워크에서 통신 하는 장치의 연결을 해제하는 방법입니다. 송신자와 수신자는 총 4번에 걸쳐 데이터를 주고 받으며 연결을 끊습니다.
7. OSI 7 layer와 각 계층에 대해 아는대로 설명해 주세요.
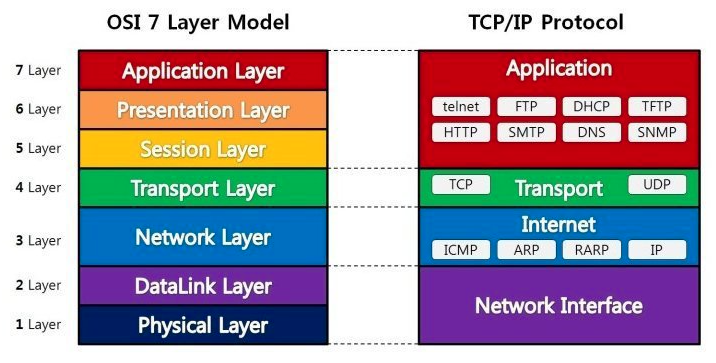 이미지 3. OSI 7 layer
이미지 3. OSI 7 layer
OSI7계층은 네트워크 통신을 구성하는 요소들 7개의 계층으로 표준화 한 것입니다. 이렇게 표준화하는 것의 장점은 통신이 일어나는 과정을 단계별로 파악할 수 있어, 문제가 발생하면 해당 문제를 해결하기 용이해집니다.
- 7 계층(응용 계층) : 사용자에게 통신을 위한 서비스 제공. 인터페이스 역할
- 6 계층(표현 계층) : 데이터의 형식(Format)을 정의하는 계층 (코드 간의 번역을 담당)
- 5 계층(세션 계층) : 컴퓨터끼리 통신을 하기 위해 세션을 만드는 계층
- 4 계층(전송 계층) : 최종 수신 프로세스로 데이터의 전송을 담당하는 계층 (단위 :Segment) (ex. TCP, UDP)
- 3 계층(네트워크 계층) : 패킷을 목적지까지 가장 빠른 길로 전송하기 위한 계층 (단위 :Packet) (ex. Router)
- 2 계층(데이터링크 계층) : 데이터의 물리적인 전송과 에러 검출, 흐름 제어를 담당하는 계층 (단위 :frame) (ex. 이더넷)
- 1 계층(물리 계층) : 데이터를 전기 신호로 바꾸어주는 계층 (단위 :bit) (장비: 케이블,리피터,허브)
8. 세션 기반 인증과 토큰 기반 인증의 차이에 대해 얘기해 주세요.
세션 기반 인증은 클라이언트로부터 요청을 받으면 클라이언트의 상태 정보를 저장하므로 Stateful한 구조를 가지고, 토큰 기반 인증은 상태 정보를 서버에 저장하지 않으므로 Stateless한 구조를 가집니다.
Stateful이란 server side에 client와 server의 동작, 상태정보를 저장하는 프로토콜이며 세션 상태에 기반하여 server의 응답이 달라집니다. 즉, Stateful은 세션이 종료될 때까지 클라이언트의 세션 정보를 저장하는 네트워크 프로토콜입니다. Stateless이란 server side에 client와 server의 동작, 상태정보를 저장하지 않는 프로토콜이며 server의 응답이 client와의 세션 상태와 독립적입니다. 즉 Stateless는 서버가 클라이언트의 세션 상태 및 세션 정보를 저장하지 않는 네트워크 프로토콜입니다.
8-1. 그렇다면 Stateful한 세션 기반의 인증 방식을 사용하게 된다면 어떠한 단점이 있을까요?
- 서버에 세션을 저장하기 때문에 사용자가 증가하면 서버에 과부하를 줄 수 있어 확장성이 낮습니다.
- 해커가 훔친 쿠키를 이용해 요청을 보내면 서버는 올바른 사용자가 보낸 요청인지 알 수 없습니다.
8-2. JWT(Json Web Token)에 대해 설명해 주세요.
JWT란 JSON 포맷을 이용해 사용자에 대한 속성을 저장하는 Claim 기반의 웹 토큰이며, 토큰 자체를 정보로 사용하는 Self-Contained(자가수용적-JWT는 필요한 모든 정보를 자체적으로 가지고 있음) 방식으로 정보를 안전하게 전달합니다. JWT는 각 파트를 .으로 구분하여 헤더(Header).내용(Payload).서명(Signature) 형식으로 구성됩니다.
Clame이란 사용자에 대한 프로퍼티나 속성을 뜻합니다.
9. RESTful에 대해 설명해 주세요.
우선 REST란, HTTP URI(Uniform Resource Identifier)를 통해 자원(Resource)을 명시하고, HTTP Method(POST, GET, PUT, DELETE)를 통해 해당 자원에 대한 CRUD Operation을 적용하는 것을 의미합니다. REST 기반으로 서비스 API를 구현한 것을 REST API라고 하며, 이러한 ‘REST API’를 제공하는 웹 서비스를 ‘RESTful’하다고 할 수 있습니다.
9-1. 그렇다면, RESTful하지 못한 경우는 어떤 것인가요?
CRUD 기능을 모두 POST로만 처리하는 API같은 경우 또는 route에 resource, id 외의 정보가 들어가는 경우 등이 있습니다.
REST는 조금더 깊게 공부하시기를 추천드립니다. 명확한 표준이 존재하지 않는다는 점 또한 RESTful을 완전히 만족하는 API를 만들기는 생각보다 까다롭습니다. 자세한 공부를 원하신다면 🌎REST란? REST API란? RESTful이란?의 포스트를 확인해주세요.</font>
🔎 개발 면접 질문 - 운영체제
1. 프로세스와 스레드의 차이를 설명해 주세요.
- 프로세스는 실행중인 프로그램을 의미합니다. 완벽히 독립적이기 때문에 메모리 영역(Code, Data, Heap, Stack)을 다른 프로세스와 공유하지 않습니다. 프로세스는 최소 1개의 쓰레드를 가지고 있습니다.
- 스레드는 실행 제어만 분리한 것을 의미합니다. 프로세스 내에서 Stack만 따로 할당 받고, 그 이외의 메모리 영역(Code, Data, Heap)영역을 공유하기 때문에 다른 쓰레드의 실행 결과를 즉시 확인할 수 있습니다. 쓰레드는 프로세스 내에 존재하며 프로세스가 할당받은 자원을 이용하여 실행됩니다.
2. 멀티 프로세스와 멀티 스레드의 특징에 대해 설명해 주세요.
- 멀티 프로세스는 하나의 프로세스가 죽어도 다른 프로세스에 영향을 끼치지 않고 계속 실행된다는 장점이 있지만 멀티 스레드보다 많은 메모리 공간과 CPU 시간을 차지한다는 단점이 있습니다.
- 멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 문맥 전환이 빠르다는 장점이 있지만 하나의 스레드에 문제가 생기면 전체 쓰레드가 영향을 받으며 동기화 문제도 있다는 단점이 있습니다. 또한, 다수의 쓰레드가 공유 데이터에 동시에 접근하는 경우에 상호배제 또는 동기화 기법을 통해 동시성 문제 또는 교착 상태가 발생하지 않도록 주의해야 합니다.
3. 멀티 스레드 프로그래밍에 대해 설명해 주세요.
멀티 스레드 프로그래밍은 하나의 프로세스에서 여러개의 스레드를 만들어 자원의 생성과 관리의 중복을 최소화하는 것을 멀티 스레드 프로그래밍이라고 합니다.
장점
- 멀티 프로세스에 비해 메모리 자원소모가 줄어듭니다.
- 힙 영역을 통해서 스레드간 통신이 가능해서 프로세스간 통신보다 간단합니다.
- 스레드의 컨텍스트 스위칭은 프로세스의 컨텍스트 스위칭보다 빠릅니다. 단점
- 힙 영역에 있는 자원을 사용할 때는 동기화를 해야합니다.
- 동기화를 위해서 락을 과도하게 사용하면 성능이 저하될 수 있습니다.
- 하나의 스레드가 비정상적으로 동작하면 다른 스레드도 종료될 수 있습니다.
3-1. 멀티 프로세스 or 멀티 스레드 프로그래밍을 해본 경험이 있나요?
저는 🌎Python GIL, Global interpreter Lock을 공부하기 위해 멀티 스레딩을 경험해 본 적이 있습니다. 이 문제는 지원자분이 멀티 프로세스 or 멀티 스레드를 구현해본 경험을 이야기 하시면 될 것 같습니다.
4. 컨텍스트 스위칭(Context Switching)에 대해 설명해 주세요.
컨텍스트 스위칭(Context Switching)은 한 Task가 끝날 때까지 기다리는 것이 아니라 여러 작업을 번갈아가며 실행해서 동시에 처리될 수 있도록 하는 방법입니다. 인터럽트가 발생하면 현재 프로세스의 상태를 PCB에 저장하고 새로운 프로세스의 상태를 레지스터에 저장하는 방식으로 동작합니다. 이 때, CPU는 아무런 일을 하지 않으므로 잦은 컨텍스트 스위칭은 성능저하를 일으킬 수 있습니다. 스레드와 프로세스의 동작방식이 약간 상이한데, 스레드는 캐시메모리나 PCB에 저장해야하는 내용이 적고, 비워야 하는 내용도 적기때문에 상대적으로 더 빠른 컨텍스트 스위칭이 일어날 수 있습니다.
5. 동기와 비동기의 차이에 대해 설명해 주세요.
동기는 순차적, 직렬적으로 테스크를 수행하고, 비동기는 병렬적으로 테스크를 수행합니다. 예를 들어, 서버에서 데이터를 가져와서 화면에 표시하는 작업을 수행할 때, 동기는 서버에 데이터를 요청하고 데이터가 응답될 때까지 이후 테스크들은 블로킹(Blocking, 작업 중단)됩니다. 비동기는 서버에 데이터를 요청한 이후 서버로부터 데이터가 응답될 때까지 대기하지 않고(Non-Blocking) 즉시 다음 테스크를 계속해 수행합니다.
6. 데드락(DeadLock)이 무엇인가요?
데드락(DeadLock) 또는 교착상태란 한정된 자원을 여러 프로세스가 사용하고자 할 때 발생하는 상황으로, 프로레스가 자원을 얻기 위해 영구적으로 기다리는 상태입니다. 예를 들어 다음과 같은 상황에서 데드락이 발생할 수 있습니다. 자원 A를 가진 프로세스 P1과 자원 B를 가진 프로세스 P2가 있을 때, P1은 B를 필요로 하고 P2는 A를 필요로 한다면 두 프로세스 P1, P2는 서로 자원을 얻기위해 무한정 기다리게 됩니다.
 이미지 4. DeadLock
이미지 4. DeadLock
7. 뮤텍스(Mutex)와 세마포어(Semaphore)의 차이에 대해 설명해 주세요.
세마포어는 여러개의 프로세스가 접근 가능한 공유자원을 관리하는 방식이고, 뮤텍스가 될 수 있지만, 뮤텍스는 한 번에 한 개의 프로세스만 접근 가능하도록 관리하는 방식입니다. 따라서 뮤텍스는 세마포어가 될 수 없습니다. 또, 세마포어는 다른 프로세스가 세마포어를 해제할 수 있지만, 뮤텍스는 락을 획득한 프로세스만 락을 반환할 수 있습니다.
8. 가상 메모리와 페이지 폴트에 대해 설명해 주세요.
가상메모리는 RAM의 부족한 용량을 보완하기 위해, 각 프로그램에 실제 메모리 주소가 아닌 가상의 메모리 주소를 할당하는 방식입니다. OS는 프로세스들의 내용(페이지) 중에서 덜 중요한 것들을 하드디스크에 옮겨 놓고, 관련 정보를 페이지 테이블에 기록합니다. CPU는 프로세스를 실행하면서 페이지 테이블을 통해 페이지를 조회하는데, 실제메모리에 원하는 페이지가 없는 상황이 발생할 수 있습니다. 이것을 페이지 폴트라고 하는데 프로세스가 동작하면서 실제메모리에 필요한 데이터(페이지)가 없으면 가상메모리를 통해서 해당 데이터를 가져오게 됩니다. 가상메모리는 하드디스크에 저장되어 있기 때문에, 페이지폴트가 발생하면 I/O에 의한 속도의 저하가 발생합니다.
9. 페이지 교체 알고리즘에 대해 설명해주세요.
페이지를 교체하는 이유는 가상메모리를 통해 조회한 페이지는 다시 사용될 가능성이 높기 때문입니다. 페이지 교체를 위해서는 실제메모리에 존재하는 페이지를 가상메모리로 저장한 후에, 가상메모리에서 조회한 페이지를 실제메모리로 로드해야 됩니다. 이 때 사용되어지는 알고리즘을 페이지 교체 알고리즘이라고 합니다. 아래는 대표적인 페이지 교체 알고리즘 입니다.
- FIFO(First In First Out) : FIFO 알고리즘은 메모리에 올라온 지 가장 오래된 페이지를 교체합니다. 간단하고, 초기화 코드에 대해 적절한 방법이며, 페이지가 올라온 순서를 큐에 저장합니다.
- LRU(Least Recently Used) : LRU 알고리즘은 실제메모리의 페이지들 중에서 가장 오랫동안 사용되지 않은 페이지를 선택하는 방식입니다.
- 추가로 참조 횟수가 가장 작은 페이지를 교체하는 알고리즘인 LFU(Least Frequently Used)와 참조 횟수가 가장 많은 페이지를 교체하는 알고리즘인 MFU(Most Frequently Used)가 있는데 구현에 상당한 비용이 들고, 최적 페이지 교체 정책을 제대로 LRU만큼 유사하게 구현해내지 못하기 때문에 실제로는 잘 사용 되어지지 않습니다.
끝맺음
공부를 하면서 질문에 괜찮은 내용이 있으면 요약하면서 계속 추가하고 있습니다. 또한, 기본적인 이론에 대해 다시 공부를 하려고 정리한 내용이기 때문에 잘못된 부분들이 있을 수도 있습니다. 잘못된 정보가 보이거나, 부족한 내용, 추가되면 좋을 것 같은 내용이 있다면 댓글에 적어주시면 감사하겠습니다!😊
[참고자료]