
💡 Intro
신입 백앤드 개발자를 위한 면접 질문 정리 - 데이터베이스에서는 데이터베이스에 대한 전반적인 면접 질문을 다루어 보려고 합니다.
🔎 개발 면접 질문 - 데이터베이스
1. SQL SELECT 쿼리 문법 순서와 실행 순서에 대해서 설명해 주세요.
- SQL 문법 순서 : SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY
- SQL 실제 실행 순서 : FROM(각 테이블 확인) -> ON(조인 조건 확인) -> JOIN(테이블 조인(병합)) -> WHERE(데이터 추출 조건 확인) -> GROUP BY(특정 칼럼으로 데이터 그룹화) -> HAVING(그룹화 이후 데이터 추출 조건 확인) -> SELECT(데이터 추출) -> DISTINCT(중복 제거) -> ORDER BY(데이터 정렬) -> LIMIT
2. 데이터베이스에서 인덱스를 사용하는 이유와 장점, 단점에 대해서 설명해 주세요.
인덱스란, 테이블을 처음부터 끝까지 검색하는 방법인 FTS(Full Table Scan)과는 달리 인덱스를 검색하여 해당 자료의 테이블을 엑세스하는 방법입니다. 즉, 인덱스를 잘 사용하면 데이터베이스의 테이블에서 필요한 데이터를 빨리 찾을 수 있다는 장점이 있습니다. 인덱스의 단점이라하면 추가, 수정, 삭제 연산시에는 인덱스를 형성하기 위한 추가적인 연산이 수행되기 때문에 실행 속도가 느릴 수 있습니다.
3. RDBMS와 NoSQL에 대해서 설명한 후 그 두 가지의 차이점에 대해서 설명해 주세요.
- RDBMS는 데이터베이스를 이루는 객체들의 릴레이션을 통해서 데이터를 저장하는 데이터베이스입니다.
- NOSQL은 RDBMS에 비해 자유로운 형태로 데이터를 저장합니다. 또한 수평확장을 할 수 있고 분산처리를 지원합니다.
RDBMS와 NoSQL의 가장 큰 차이점은 RDBMS는 정해진 스키마가 존재하지만, NoSQL은 정해진 스키마가 없다는 것입니다. NoSQL은 정해진 스키마가 없을 때 데이터 구조 변화가 자유롭고 데이터 분산이 용이하다는 장점이 있지만, 데이터 중복 또는 변경시에 연산이 오래걸릴 수 있다는 단점이 있습니다.
4. 트랜잭션에 대해서 설명해 주세요.
트랜잭션이란 데이터베이스의 상태를 변화시키는 하나의 논리적인 작업 단위라고 할 수 있으며, 작업의 완전성을 보장해 줍니다. 즉, 작업들을 모두 처리하거나 처리하지 못할 경우 이전 상태로 복구하여 작업의 일부만 적용되는 현상이 발생하지 않게 해줍니다.
4-1. 트랜잭션의 ACID에 대해서 설명해 주세요.
ACID는 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질입니다.
- Atomicity(원자성) : 트랜잭션의 연산은 모든 연산이 완벽히 수행되어야 하며, 한 연산이라도 실패하면 트랜잭션은 실패해야 합니다.
- Consistency(일관성) : 트랜잭션을 수행하기 전이나 후나 데이터베이스는 항상 일관된 상태를 유지해야 합니다.
- Isolation(고립성) : 트랜잭션은 동시에 실행될 경우 다른 트랜잭션에 의해 영향을 받지 않고 독립적으로 실행되어야 합니다.
- Durability(지속성) : 트랜잭션이 완료된 이후에는 시스템 오류가 발생하더라도 완료된 상태로 영구히 저장되는 것을 보장해야 합니다.
4-2. 트랜잭션 격리 수준(Transaction Isolation Levels)에 대해서 설명해 주세요.
- READ UNCOMMITTED : 다른 트랜잭션에서 커밋되지 않은 내용도 참조할 수 있습니다.
- READ COMMITTED : 다른 트랜잭션에서 커밋된 내용만 참조할 수 있습니다.
- REPEATABLE READ : 트랜잭션에 진입하기 이전에 커밋된 내용만 참조할 수 있습니다.
- SERIALIZABLE : 트랜잭션에 진입하면 락을 걸어 다른 트랜잭션이 접근하지 못하도록 합니다.(성능이 매우 떨어질 수 있음)
5. DB Lock에 대해 설명해주세요.
DB Lock은 트랜잭션 처리의 순차성을 보장하기 위한 방법입니다.
- 공유락(LS, Shared Lock) : Read Lock라고도 하는 공유락은 트랜잭션이 읽기를 할 때 사용하는 락이며, 데이터를 읽기만 하기 때문에 같은 공유락 끼리는 동시에 접근이 가능합니다.
- 베타락(LX, Exclusive Lock) : Write Lock라고도 하는 베타락은 데이터를 변경할 때 사용하는 락입니다. 트랜잭션이 완료될 때까지 유지되며, 베타락이 끝나기 전까지 어떠한 접근도 허용하지 않습니다.
6. 정규화에 대해서 설명해 주세요.
정규화는 데이터의 중복방지, 무결성을 충족시키기 위해 데이터베이스를 설계하는 것을 의미합니다.
- 제1정규형 : 모든 속성 값이 원자 값을 갖도록 분해합니다.
- 제2정규형 : 제1정규형을 만족하고, 기본키가 아닌 속성이 기본키에 완전 함수 종속이도록 분해합니다.(여기서 완전 함수 종속이란 기본키의 부분집합이 다른 값을 결정하지 않는 것을 의미합니다.)
- 제3정규형 : 제2정규형을 만족하고, 기본키가 아닌 속성이 기본키에 직접 종속(비이행적 종속)하도록 분해합니다.(여기서 이행적 종속이란 A->B->C가 성립하는 것으로, 이를 A,B와 B,C로 분해하는 것이 제3정규형입니다.)
- BCNF 정규형 : 제3정규형을 만족하고, 함수 종속성 X->Y가 성립할 때 모든 결정자 X가 후보키가 되도록 분해합니다.
7. 이상 현상에 대해서 설명해 주세요.
이상 현상은 테이블을 설계할 때 잘못 설계하여 데이터를 삽입,삭제,수정할 때 생기는 논리적 오류를 말합니다. 이상 현상의 종류는 다음과 같습니다.
- 삽입 이상 : 자료를 삽입할 때 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 수정 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
- 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
8. Redis에 대해서 간단히 설명해 주세요.
Redis는 key-value store NOSQL DB입니다. 싱글스레드로 동작하며 자료구조를 지원합니다. 그리고 다양한 용도로 사용될 수 있도록 다양한 기능을 지원합니다. 데이터의 스냅샷 혹은 AOF 로그를 통해 복구가 가능해서 어느정도 영속성도 보장됩니다.
8-1. 그렇다면 Redis를 왜 사용하나요?
사용자가 늘어남에 따라 DB에 부하가 가해지기 시작합니다. 이 부하를 줄이기 위해 한 번 읽어온 데이터를 저장하고, 다시 요청하는 경우 빠르게 결과 값을 받을 수 있도록(캐싱) 하기 위해 Redis를 사용합니다.
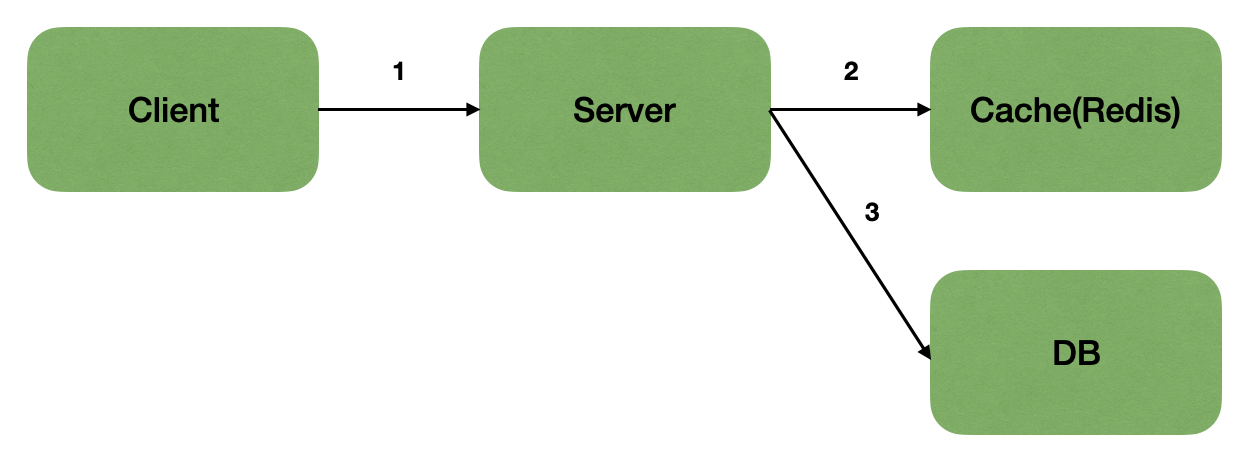 이미지 1. Redis
이미지 1. Redis
여기서 캐시가 Redis가 되며 look aside cache 기준으로 가장 먼저 캐시에 데이터가 있는지 확인하고, 데이터가 있으면 캐시 데이터 사용합니다. 데이터가 없으면 실제 DB데이터 사용한 후 DB데이터를 캐시에 저장합니다.
9. Elasticsearch에 대해서 설명해 주세요.
Apache Lucene(아파치 루씬) 기반의 java 오픈소스 분산 검색 엔진이며, 역색인(Inverted Index) 구조로 데이터를 저장해서, 전체 텍스트 검색시에 RDBMS에 비해 뛰어난 성능을 보장합니다. 또한, 데이터 저장소가 아니기 때문에 관계형 데이터베이스(RDBMS: mysql, oracle, mariadb)를 대체할 수 없습니다.
🌎역색인(Inverted Index)이란? 주어진 키워드에 대해서 해당 키워드가 포함된 데이터의 위치를 추적해내는 것을 의미합니다. 쉽게 말해서 색인은 데이터베이스 내의 데이터들로부터 키워드를 뽑아내는 과정이라면, 역색인은 특정 키워드에 대해 요청(Request)이 들어왔을때 해당 키워드들을 포함하고 있는 데이터들을 찾아내는 것을 의미합니다. 색인(Index)을 책 맨 앞의 목차라고 한다면, 역색인(Inverted Index)은 책 맨 뒷 부분의 색인이라고 할 수 있습니다.
9-1. Elasticsearch의 인덱스 구조와 RDBMS의 인덱스 구조의 차이에 대해 설명해 주세요.
Elasticsearch는 역색인(Inverted Index) 구조로 데이터를 저장합니다. 반면 RDBMS는 B-Tree와 그와 유사한 인덱스를 사용합니다. 데이터가 어디에 존재하는지, 또는 어떤 순서로 저장하는지의 차이라고 생각합니다.
9-2. Elasticsearch의 키워드 검색과 RDBMS의 LIKE 검색의 차이에 대해 설명해 주세요.
RDBMS는 단순 텍스트매칭에 대한 검색만을 제공해 동의어나 유의어 같은 검색은 불가능합니다. 하지만 Elasticsearch는 동의어나 유의어를 활용한 검색이 가능하며, 비정형 데이터의 색인과 검색이 가능하고, 역색인(Inverted Index) 지원으로 매우 빠른 검색이 가능합니다.
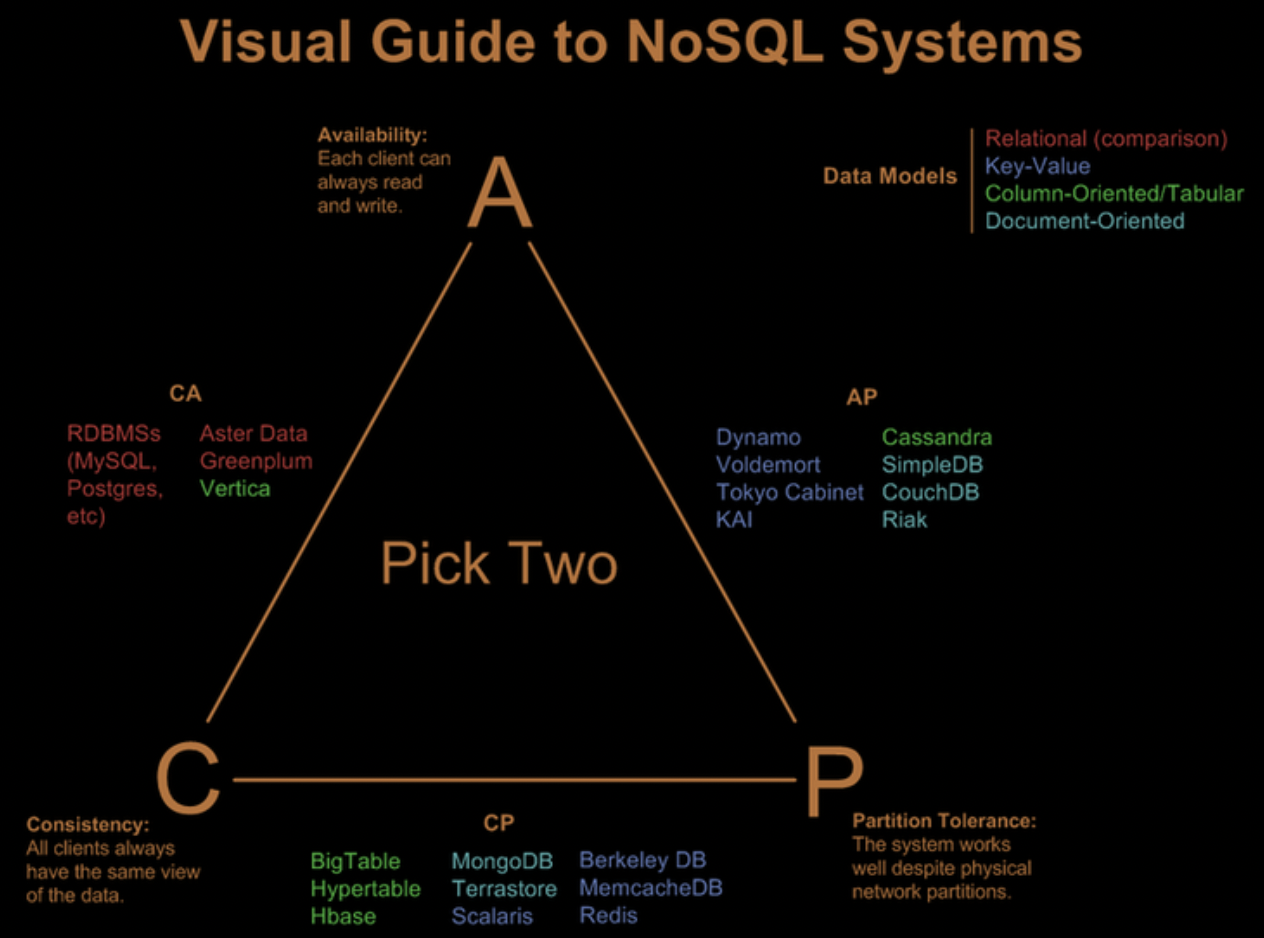
10. CAP 이론과, Eventual Consistency에 대해서 설명해 주세요.
이미지 2. CAP 이론
CAP 이론은 분산 환경에서 모두를 만족하는 시스템은 없다는 이론입니다. 즉, CAP 세 가지 속성을 모두 만족하는 부분은 존재하지 않으며, 오직 두 가지만 만족할 수 있다로 정리되는 이론입니다.
- Consitenty(일관성) : ACID의 일관성과는 약간 다릅니다. 모든 노드가 같은 시간에 같은 데이터를 보여줘야 한다는 것입니다.
- Availability(가용성) : 모든 동작에 대한 응답이 리턴되어야 합니다.
- Partition Tolerance(분할 내성) : 시스템 일부가 네트워크에서 연결이 끊기더라도 동작해야 합니다.
Eventual Consistency이란, Consistency를 보장해주지 못하기 때문에 나온 개념으로, Consistency를 완전히 보장하지는 않지만 결과적으로 언젠가는 Conssistency가 보장됨을 의미합니다.
CAP 이론은 허점이 있는데, 그 허점에 대한 내용과 CAP 이론으로 부족한 부분을 보완하기위해 나온 PACELC 이론은 🌎CAP 이론과 PACELC 이론에서 자세한 내용을 다루어 볼 수 있습니다.
11. ORM(Object Relational Mapping)에 대해서 설명해 주세요.
ORM(Object Relational Mapping)이란, 객체와 관계형 데이터베이스 매핑의 줄임말 입니다. 우리가 OOP(Object Oriented Programming)에서 쓰는 객체라는 개념을 구현한 클래스와 RDB(Relational DataBase)에서 쓰이는 데이터인 테이블을 매핑하는 것을 의미합니다.
※ 추가로, SQLAlchemy 혹은 Django ORM등 본인이 사용한 ORM을 예시로 들며 추가 설명을 해주면 좋을 것 같습니다.
12. Replciation과 Clustering에 대해 설명해 주세요.
🧩 리플리케이션(Replciation)
- 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식입니다.
- 비동기 방식으로 노드들 간의 데이터를 동기화합니다.
- 장점 : 비동기 방식으로 데이터가 동기화되어 지연 시간이 거의 없습니다.
- 단점 : 노드들 간의 데이터가 동기화되지 않아 일관성있는 데이터를 얻지 못할 수 있습니다.
🧩 클러스터링(Clustering)
- 여러 개의 DB를 수평적인 구조로 구축하여 Fail Over한 시스템을 구축하는 방식입니다.
- 동기 방식으로 노드들 간의 데이터를 동기화합니다.
- 장점 : 1개의 노드가 죽어도 다른 노드가 살아 있어 시스템을 장애없이 운영할 수 있습니다.
- 단점 : 여러 노드들 간의 데이터를 동기화하는 시간이 필요하므로 리플리케이션에 비해 쓰기 성능이 떨어집니다.
13. 데이터베이스 튜닝(Tuning)과 방법에 대해서 설명해 주세요.
DB 튜닝이란 DB의 구조나, DB 자체, 운영체제 등을 조정하여 DB 시스템의 전체적인 성능을 개선하는 작업을 말합니다. 튜닝은 DB 설계 튜닝 → DBMS 튜닝 → SQL 튜닝 단계로 진행할 수 있습니다.
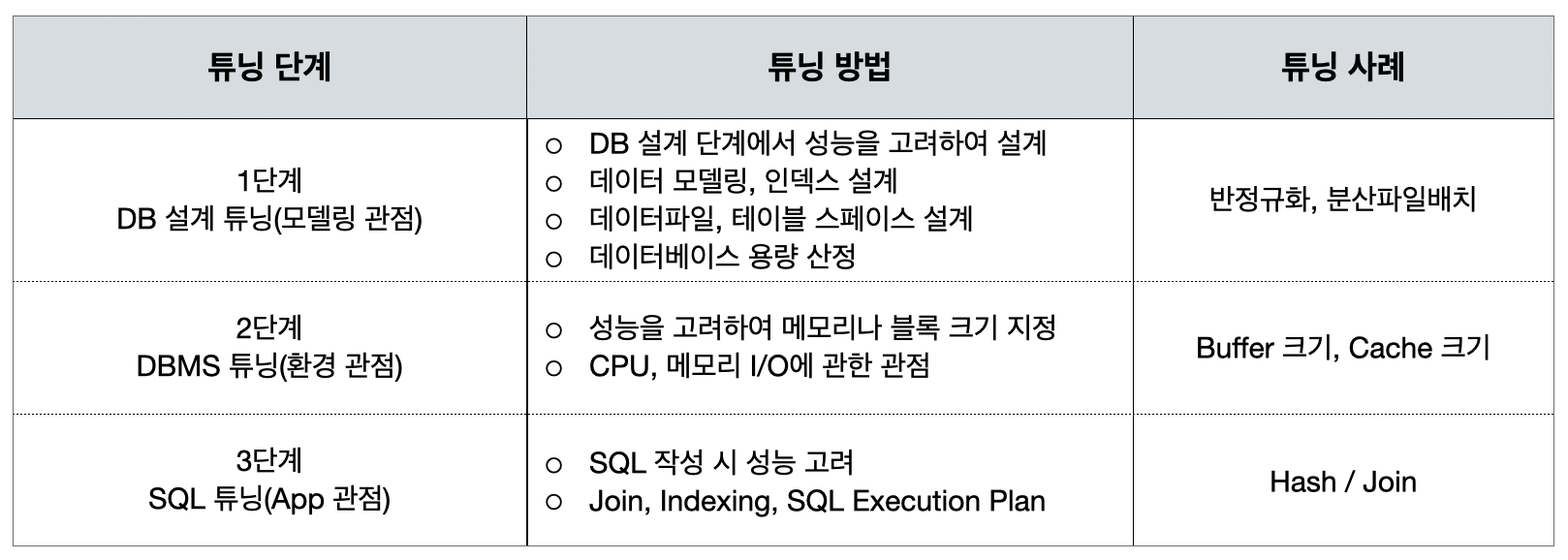 표 1. DB tuning
표 1. DB tuning
14. ELK Stack에 대해서 설명해 주세요.
ELK는 분석 및 저장 기능을 담당하는 ElasticSearch, 수집 기능을 하는 Logstash, 이를 시각화하는 도구인 Kibana의 앞글자만 딴 단어이며, ELK는 접근성과 용이성이 좋아 최근 가장 핫한 Log 및 데이터 분석 도구입니다.
- Elasticsearch : ElasticSearch는 Lucene 기반으로 개발한 분산 검색엔진으로, Logstash를 통해 수신된 데이터를 저장소에 저장하는 역할을 담당합니다.(자세한 내용은, 9번 문제로 가주세요.😊)
- Logstash : 오픈소스 서버측 데이터 처리 파이프라인으로, 다양한 소스에서 동시에 데이터를 수집하고 변환하여 stash 보관소로 보냅니다.
- Kibana : 데이터 시각화 및 탐색 툴로 Elasticsearch 상의 데이터를 쉽게 다룰 수 있게 해줍니다.
주로 묶어서 많이 사용하기 때문에 ELK라고 부르지만, 각각의 도구들 전부 확장성이 뛰어나기 때문에 다른 도구로 대체 혹은 제외가 가능합니다.
추가로, Logstash는 데이터 수집의 역할을 맡고 있으면서, 원하는 형태로의 데이터 입출력 변환 기능까지 맡고 있었기 때문에, 데이터의 수집(파일 추적 등의 여러 단일 목적 데이터 수집 제품들)만을 담당하는 경량화된 모듈 Beats가 도입되었습니다. 그로 인해 기존의 ELK Stack은 Beats가 포함되어 Elastic Stack이 되었습니다. 따라서 Elastic Stack의 Data Flow는 아래 이미지와 같습니다.
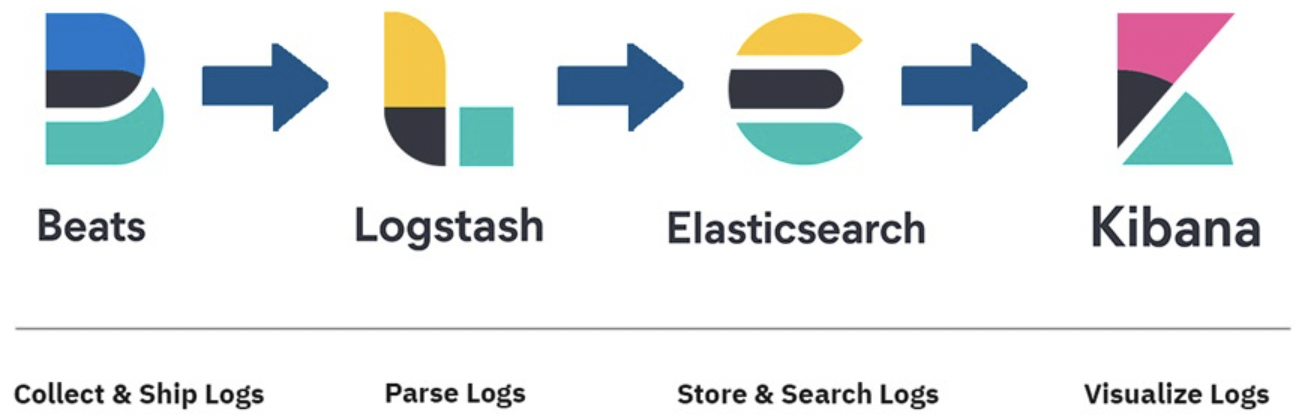 이미지 3. Elastic Stack의 Data Flow
이미지 3. Elastic Stack의 Data Flow
끝맺음
공부를 하면서 질문에 괜찮은 내용이 있으면 요약하면서 계속 추가하고 있습니다. 또한, 기본적인 이론에 대해 다시 공부를 하려고 정리한 내용이기 때문에 잘못된 부분들이 있을 수도 있습니다. 잘못된 정보가 보이거나, 부족한 내용, 추가되면 좋을 것 같은 내용이 있다면 댓글에 적어주시면 감사하겠습니다!😊
[참고자료]